
Each time I visited a Crescent Road, I filled out a form, noting down information on the location of the road, the types of houses there and the traffic. I also wrote down descriptions of what was happening. You can view the information for each of the Crescent Roads below, or view my analysis of the data.
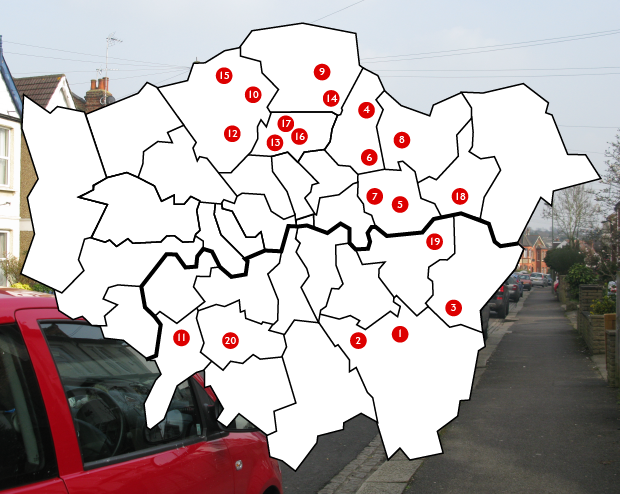
Select a number on the map to find out more about that Crescent Road
 BR1 Sundridge Park (Bromley)
BR1 Sundridge Park (Bromley)
Terraced: 0
Semi-Detached: 35
Detached: 12
Flats (Blocks): 2
Car Count (5min): 4
Pedestrian Count (5min): 4
 BR3 Beckenham (Bromley)
BR3 Beckenham (Bromley)
Terraced: 0
Semi-Detached: 18
Detached: 13
Flats (Blocks): 3
Car Count (5min): 6
Pedestrian Count (5min): 10
 DA15 Sidcup (Bexley)
DA15 Sidcup (Bexley)
Terraced: 6
Semi-Detached: 6
Detached: 38
Flats (Blocks): 0
Car Count (5min): 6
Pedestrian Count (5min): 6
 E4 Chingford (Waltham Forest)
E4 Chingford (Waltham Forest)
Terraced: 0
Semi-Detached: 6
Detached: 11
Flats (Blocks): 5
Car Count (5min): 3
Pedestrian Count (5min): 3
 E6 Upton Park (Newham)
E6 Upton Park (Newham)
Terraced: 6
Semi-Detached: 0
Detached: 1
Flats (Blocks): 5
Car Count (5min): 6
Pedestrian Count (5min): 35
 E10 Leyton (Waltham Forest)
E10 Leyton (Waltham Forest)
Terraced: 24
Semi-Detached: 5
Detached: 2
Flats (Blocks): 3
Car Count (5min): 1
Pedestrian Count (5min): 9
 E13 Plaistow (Newham)
E13 Plaistow (Newham)
Terraced: 19
Semi-Detached: 24
Detached: 5
Flats (Blocks): 0
Car Count (5min): 5
Pedestrian Count (5min): 8
 E18 South Woodford (Redbridge)
E18 South Woodford (Redbridge)
Terraced: 17
Semi-Detached: 39
Detached: 0
Flats (Blocks): 1
Car Count (5min): 1
Pedestrian Count (5min): 8
 EN2 Enfield Chase (Enfield)
EN2 Enfield Chase (Enfield)
Terraced: 0
Semi-Detached: 2
Detached: 1
Flats (Blocks): 5
Car Count (5min): 6
Pedestrian Count (5min): 5
 EN4 East Barnet (Barnet)
EN4 East Barnet (Barnet)
No data collected
 KT2 Coombe (Kingston Upon Thames)
KT2 Coombe (Kingston Upon Thames)
Terraced: 17
Semi-Detached: 50
Detached: 19
Flats (Blocks): 5
Car Count (5min): 8
Pedestrian Count (5min): 8
 N3 Finchley Central (Barnet)
N3 Finchley Central (Barnet)
Terraced: 3
Semi-Detached: 2
Detached: 8
Flats (Blocks): 2
Car Count (5min): 2
Pedestrian Count (5min): 5
 N8 Crouch End (Haringey)
N8 Crouch End (Haringey)
Terraced: 0
Semi-Detached: 4
Detached: 12
Flats (Blocks): 10
Car Count (5min): 11
Pedestrian Count (5min): 9
 N9 Edmonton Green (Enfield)
N9 Edmonton Green (Enfield)
Terraced: 11
Semi-Detached: 10
Detached: 0
Flats (Blocks): 0
Car Count (5min): 5
Pedestrian Count (5min): 3
 N11 Friern Barnet (Barnet)
N11 Friern Barnet (Barnet)
Terraced: 0
Semi-Detached: 14
Detached: 0
Flats (Blocks): 0
Car Count (5min): 15
Pedestrian Count (5min): 4
 N15 Turnpike Lane (Haringey)
N15 Turnpike Lane (Haringey)
Terraced: 17
Semi-Detached: 0
Detached: 0
Flats (Blocks): 0
Car Count (5min): 7
Pedestrian Count (5min): 11
 N22 Wood Green (Haringey)
N22 Wood Green (Haringey)
Terraced: 51
Semi-Detached: 30
Detached: 2
Flats (Blocks): 2
Car Count (5min): 18
Pedestrian Count (5min): 20
 RM10 Dagenham East (Barking & Dagenham)
RM10 Dagenham East (Barking & Dagenham)
Terraced: 126
Semi-Detached: 26
Detached: 0
Flats (Blocks): 0
Car Count (5min): 4
Pedestrian Count (5min): 3
 SE18 Woolwich Arsenal (Greenwich)
SE18 Woolwich Arsenal (Greenwich)
Terraced: 119
Semi-Detached: 2
Detached: 0
Flats (Blocks): 1
Car Count (5min): 26
Pedestrian Count (5min): 12
 SW20 South Wimbledon (Merton)
SW20 South Wimbledon (Merton)
Terraced: 0
Semi-Detached: 4
Detached: 18
Flats (Blocks): 2
Car Count (5min): 0
Pedestrian Count (5min): 2
Conclusions
Collecting the data, I found myself adopting the role of either a geographer, someone working for the local council, or a very niche suburban trainspotter. Sadly I didn’t have a little clicker to take the car and pedestrian counts with, or a suitably shapeless anorak. But the process was as much about the performance of being an outsider travelling across the city to measure seemingly meaningless things as it was about the data itself.
Trying desperately to remember my Geography GCSE, and closely studying Jan Gehl's urban planning bible 'Life Between Buildings', I tried to apply the scientific method to my data. I started my analysis by finding an ‘average’ Crescent Road from the 20 samples I have collected. Here’s the results:
Car Count (5min): 0 Pedestrian Count (5min): 2
With this data I could compare each Crescent Road to a general idea of what the average Crescent Road was like. Number 5 (E6), for example, has an very high pedestrian count - 35, relative to the average - 9. Number 20 (SW20) has a comparatively low pedestrian count, of only 2, and I counted no cars at all.
Unfortunately, this data means nothing when we have nothing to compare it to. Is 7 cars every 5 minutes busier or quieter than the average? And what average do I mean by that - the average for residential roads? Another issue I discovered with the data was that I had collected it at different times of day. I visited Number 5 at 17:00 on a Sunday, so naturally the pedestrian count will be larger than Number 9 (EN2), which I visited on a Monday at 13:00. To truly make the data comparable, I should’ve visited each road at the same time of day, and probably on the same day of the week. Plus, extrapolating the traffic counts to find the number of cars and pedestrians per hour (by multiplying by 12) makes the data very unreliable. 5 minutes is not representative of a whole hour.
So with the traffic data rendered useless by poor methodology, maybe the house data will tell us something. Using statistics from the London Data Store, I compared the makeup of Number 4 (E4) against the makeup of Waltham Forest borough:
| Crescent Road No.4 | Waltham Forest Borough | |
| Terraced | 0% | 44% |
| Semi-Detached | 27% | 9% |
| Detached | 50% | 1% |
| Flats (Blocks) | 23% | 43% |
As you can see, Number 4 is not typical for the borough. It has no terraced houses and a much higher percentage of detached houses. But the borough data is taken from roads of all types - from quiet residential roads to busy high streets. So we are effectively comparing the Crescent Roads to the entirety of London’s urban fabric, which seems pointless. When this comparison is done to all the Crescent Roads, there is no consensus: they neither fit, or don't fit, the typical makeup of their boroughs. Below you can see the difference (in %) between the Crescent Roads' data and that of their respective boroughs.
| Crescent Road | % Difference | |||
| Terraced | Semi-D. | Detached | Flats | |
| 1 (Bromley) | 24 | 46 | 9 | 26 |
| 2 (Bromley) | 24 | 28 | 23 | 21 |
| 3 (Bexley) | 16 | 25 | 71 | 24 |
| 4 (Waltham Forest) | 44 | 18 | 49 | 20 |
| 5 (Newham) | 4 | 2 | 7 | 8 |
| 6 (Waltham Forest) | 27 | 6 | 5 | 34 |
| 7 (Newham) | 6 | 48 | 9 | 50 |
| 8 (Redbridge) | 13 | 50 | 3 | 31 |
| 9 (Enfield) | 38 | 8 | 9 | 24 |
| 10 (Barnet) | - | - | - | - |
| 11 (Kingston) | 2 | 27 | 10 | 33 |
| 12 (Barnet) | 1 | 12 | 44 | 22 |
| 13 (Haringey) | 33 | 11 | 45 | 23 |
| 14 (Enfield) | 14 | 31 | 4 | 39 |
| 15 (Barnet) | 19 | 75 | 9 | 45 |
| 16 (Haringey) | 67 | 4 | 1 | 61 |
| 17 (Haringey) | 27 | 31 | 1 | 59 |
| 18 (B&D) | 23 | 9 | 0 | 30 |
| 19 (Greenwich) | 63 | 11 | 2 | 47 |
| 20 (Merton) | 45 | 5 | 71 | 31 |
Not only are the results inconclusive, but when you see the raw data, you realise how incomparable it is. How can we compare house counts in dozens against house counts in thousands? And what am I looking for, anyway - some indication that Crescent Roads are ‘average’ or ‘normal’?
My data consistently lead to dead ends like these. In the end, I figured the problem was with my methodology. I was looking for a specific answer from the data I was collecting, and that was not an ethical or productive method. I think I was secretly hoping all the Crescent Roads would have something in common, and that they would all be fantastically average, with rows of semi-detached houses and below-average traffic. Reality, however, disagreed. The reality of the roads wasn't as simple as the idea of suburbia. The city is complex, diverse and never consistent.
My unspoken hypothesis was that all Crescent Roads would be the same as the one I grew up on, and that was proven wrong. I assumed that 20 roads that shared a name would share more than that, but ultimately they didn’t. What I've learned is that the city is not a homogenous mass of endless Metroland suburbs, or that every street is only different from every other street by its location, but that London is infinitely various, and that roads that initially seem similar in fact hold a wealth of differences. As for the name - few of these roads were even crescent-shaped, so that shows how relevant that is to placemaking.